Електронна пошта - сервіс з пересилання і отримання електронних повідомлень по мережі.
Електронна пошта за складом елементів та принципу роботи практично повторює систему звичайної (паперової) пошти, запозичуючи як терміни (пошта, лист, конверт, вкладення, ящик, доставка та інші), так і характерні особливості-простоту використання, затримки передачі повідомлень, достатню надійність і в той же час відсутність гарантії доставки.
Трохи про історію електронної пошти та її творця Рея Томлісон дивіться у відео:
Перевагами електронної пошти є ті:
що легко сприймаються і запам'ятовуються людиною адреси виду username @ domainname (наприклад, somebody@example.com);
які мають можливість передачі як простого тексту, так і форматированного, а також довільних файлів;
які мають незалежність серверів (в загальному випадку вони звертаються один до одного безпосередньо);
які мають досить високу надійність доставки повідомлення; простоту використання людиною і програмами.
Недоліки електронної пошти:
наявність такого явища, як спам (масові рекламні та вірусні розсилки);
можливі затримки доставки повідомлення (до декількох діб);
обмеження на розмір одного повідомлення і на загальний розмір повідомлень в поштовій скриньці (персональні для користувачів).
В електронній пошті e-mail використовують не один прикладний протокол, як в інших службах Інтернету, а два. По одному протоколу відбувається відправка пошти, а по іншому - її прийом. Необхідність в двох протоколах пов'язана з вимогами безпеки. Так, наприклад, при відправці повідомлень можна не перевіряти особу відправника - це аналогічно тому, що лист кинуто в вуличний поштову скриньку. Інша справа - отримання повідомлень. Тут треба пред'явити свої права і пройти ідентифікацію. Так, наприклад, при отриманні рекомендованих листів в поштовому відділенні завжди необхідно пред'явити паспорт або замінюючий його документ. Кому потрапило чужу пошту в руки не віддадуть.
Для відправки на сервер і для пересилки між серверами використовують протокол, який називається SMTP (Simple Mail Transfer Protocol - найпростіший протокол передачі повідомлень). Він не вимагає ідентифікації особистості.
Для отримання надійшла пошти використовується протокол РОРЗ (Post Office Protocol 3 - протокол поштового відділення, версія 3). Він вимагає ідентифікації особистості, тобто має бути пред'явлено реєстраційне ім'я (Login) і пароль (Password), який підтверджує правомочність використання імені.
Протоколи SMTP і POP3 є прикладними протоколами, тобто вони надбудовані над базовими протоколами Інтернету TCP / IP.
Поштовий клієнт - програма, призначена для отримання, написання і зберігання електронної пошти.
Окно почтового клиента The Bat!
Найпопулярніші поштові клієнти:
Mozilla Thunderbird - сучасна програма для роботи з електронною поштою. Підтримує протоколи SMTP, POP3, IMAP, RSS. Thunderbird працює в операційних системах: Windows, Mac OS X і Linux. Програма має простий, гнучко настроюється інтерфейс.
The Bat! - одна з найбільш вдалих і потужних програм для роботи з електронною поштою. Дозволяє працювати з необмеженою кількістю поштових скриньок (протоколи POP3, IMAP4, SMTP і APOP), має регульований систему фільтрів, редактор тексту з форматуванням, а також вміє перевіряти орфографію.
Outlook Express і Windows Mail - стандартні програми для роботи з електронною поштою від усім відомої компанії Microsoft. Outlook Express поставляється в складі операційних систем Windows XP, Windows Mail - в складі Windows Vista.
На сьогодні існує два види електронної пошти:
Класична e-mail- використовує поштові протоколи і поштові клієнти
Web-пошта - обслуговується службою WWW
Класична електронна пошта має спрямований характер. Тобто в ній важливо не розташування кінцевого адресата, а маршрут переміщення листи. Отже, отримати доступ до такого поштової скриньки користувач зможе тільки на тому комп'ютері, на якому встановлено поштовий клієнт, який створив його обліковий запис.
Цього недоліку позбавлена веб- пошта. Як сервери веб пошти виступають звичайні веб сервери. Вони працюють в парі з базою даних і кожного клієнта формують при підключенні веб-сторінку, що відповідає поточному стану його облікового запису в базі даних.
Web-mail, на відміну від e-mail, не є самостійною службою. Це просто ще один додатковий сервіс загальної служби WWW З точки зору користувача різниця між ними може бути як величезної, так і непомітною взагалі.
Интерфейс веб-почты Gmail
Переваги веб-мейл:
простота використання
мобільність
відносна анонімність
простота управління обліковим записом
І недоліки:
непредставницькість
низька швидкість роботи
обмеженість корисних функцій
загроза безпеки
проблеми з кодуваннями
Поштова система дозволяє організувати складні системи, засновані на пересилання пошти від одного до багатьох абонентам.
Поштові розсилки - лист від однієї адреси з однаковим (або змінним за шаблоном) вмістом, що розсилається передплатникам розсилки.
Групи листування - спеціалізований тип поштової розсилки, в якій лист на адресу групи (звичайну поштову адресу, обробкою пошти якого займається спеціалізована програма) розсилається всім учасникам групи.
Непрохані розсилки називаються спамом. Спам - це розсилка комерційної, політичної та іншої реклами або іншого виду повідомлень особам, які не виражав бажання їх отримувати.
Види спаму:
Реклама
Реклама незаконної продукції
Антиреклама і наклеп
«Нігерійські листи»
фішинг
«Листи щастя»
Масове розсилання для виведення поштової системи з ладу (DoS-атака).
Скетч групи "Монті Пайтон" про спам:
Инфографика о спаме от Евгения Касперского (рисунок кликабелен, можно увеличить):
Пошукові каталоги являють собою довідники, в яких всі сайти знаходяться в алфавітному або тематичному порядку. Відмінністю каталогів від пошукових систем є те, що каталоги не використовують павуків, які шукають сторінки по всьому інтернету.
У той час як пошукові машини приймають майже будь-які сайти, без вимог до якості, каталоги ж, як правило, висувають вимоги до якості та змісту сайту. Так як в найбільш великих і відомих каталогах сайти перевіряються людьми, то низькоякісні сайти не потрапляють в базу даних. У каталогах реєструють зазвичай тільки головну сторінку сайту (ще одна відмінність від пошуковиків).
Історія створення першого каталогу
У 1994 році, студенти Стенфордського університету, Джеррі Янг і Девід Філо, готувалися до захисту дисертації в галузі комп'ютерного проектування інтегральних схем. Для цього їм доводилося багато часу проводити в мережі Інтернет, в пошуках потрібної інформації і збирати посилання. Списки з посиланнями росли, потім Янг і Філо закинули дисертацію і взялися виключно колекціонувати посилання. До середини 1994 року їхня стало багато, вони відсортували посилання за категоріями, потім в категоріях посилань стало теж багато, з'явилися підкатегорії.
І хто б міг подумати, що у найуспішнішого проекту www.yahoo.com власний пошук з'явився відносно недавно! Але список Джеррі і Девіда не був призначений для загального огляду - він складався виключно для друзів. Час минав, а відвідуваність все росла і росла. Адреса сайту пішов по руках ....
Першим кроком до успіху стало нове, такого назва - Yahoo !. Дотримуючись побажань користувачів, творці www.Yahoo.com, стали перетворювати сайт. З'явилися нові категорії, і розділи "What's New" і "What's Cool". До кінця 1994 Янг і Філо закинули свої дисертації і повністю віддалися роботі над пошуковою системою Яху.
В цей час на дорозі з'явилася компанія Netscape, яка запропонувала ресурси для утримання пошукової системи Yahoo !. В результаті у Yahoo! з'явився свій домен - yahoo.com, і каталог переїхав на 10 станцій Silicon Graphics Indy. Приблизно в цей же час Yahoo! отримав і першого інвестора - інвестиційний фонд "Seqouia Capital". Джеррі і Янг обзавелися офісами і найняли енергійну команду web-серферів. Темп росту склав, в середньому, 1000 сторінок в день.
Детальніше про історію Yahoo і Google дивіться в документальному фільмі "Завантаження: справжня історія інтернету"
Пошукова система - це комп'ютерна система, призначена для пошуку інформації. Одне з найбільш відомих застосувань пошукових систем - веб-сервіси для пошуку текстової або графічної інформації в інтернеті. Існують також системи, здатні шукати файли на FTP-серверах, товари в інтернет-магазинах, інформацію в групах новин Usenet.
Для пошуку інформації за допомогою пошукової системи користувач формулює запит. Робота пошукової системи полягає в тому, щоб за запитом користувача знайти документи, що містять або зазначені ключові слова, або слова, будь-яким чином пов'язані з ключовими словами. При цьому пошукова система генерує сторінку результатів пошуку. Така пошукова видача може містити різні типи результатів, наприклад: сторінки, зображення, аудіофайли. Деякі пошукові системи також витягають інформацію з відповідних баз даних і каталогів ресурсів в Інтернеті.
Пошукова система тим краще, чим більше документів, релевантних запиту користувача, вона буде повертати. Результати пошуку можуть ставати менш релевантними через особливості алгоритмів або внаслідок людського фактора. Станом на 2015 рік найпопулярнішою пошуковою системою в світі є Google, однак є країни, де користувачі віддали перевагу іншим пошуковикам. Так, наприклад, в Росії «Яндекс» обганяє Google більше, ніж на 10%.
Як працює пошукова система?
За методами пошуку і обслуговування поділяють чотири типи пошукових систем:
системи, що використовують пошукові роботи
мета-системи.
системи, керовані людиною
гібридні системи
В архітектуру пошукової системи зазвичай входять:
пошуковий робот, який збирає інформацію з сайтів мережі Інтернет або з інших документів,
індексатор, що забезпечує швидкий пошук по накопиченої інформації, і
пошуковик - графічний інтерфейс для роботи користувача.
Як правило, системи працюють поетапно. Спочатку пошуковий робот отримує контент, потім індексатор генерує доступний для пошуку індекс, і нарешті, пошуковик забезпечує функціональність для пошуку індексованих даних. Щоб оновити пошукову систему, цей цикл індексації виконується повторно.
Пошукові системи працюють, зберігаючи інформацію про багатьох веб-сторінках, які вони отримують з HTML сторінок. Пошуковий робот або «краулер» - програма, яка автоматично проходить по всіх посиланнях, знайденим на сторінці, і виділяє їх. Краулер, грунтуючись на посиланнях або виходячи із заздалегідь заданого списку адрес, здійснює пошук нових документів, ще не відомих пошуковій системі. Власник сайту може виключити певні сторінки за допомогою robots.txt, використовуючи який можна заборонити індексацію файлів, сторінок або каталогів сайту.
Пошукова система аналізує вміст кожної сторінки для подальшого індексування. Слова можуть бути вилучені із заголовків, тексту сторінки або спеціальних полів - метатегов. Індексатор - це модуль, який аналізує сторінку, попередньо розбивши її на частини, застосовуючи власні лексичні та морфологічні алгоритми. Всі елементи веб-сторінки вичленяються і аналізуються окремо. Дані про веб-сторінках зберігаються в індексному базі даних для використання в повторних запитів. Індекс дозволяє швидко знаходити інформацію за запитом користувача.Ряд пошукових систем, подібних Google, зберігають вихідну сторінку цілком або її частину, так званий кеш, а також різну інформацію про веб-сторінці. Інші системи, подібні системі AltaVista, зберігають кожне слово кожної знайденої сторінки.
Використання кешу допомагає прискорити вилучення інформації з уже відвіданих сторінок. Кешовані сторінки завжди містять той текст, який користувач задав в пошуковому запиті. Це може бути корисно в тому випадку, коли веб-сторінка оновилася, тобто вже не містить текст запиту користувача, а сторінка в кеші ще стара. Ця ситуація пов'язана з втратою посилань і дружнім по відношенню до користувача підходом Google. Це передбачає видачу з кешу коротких фрагментів тексту, що містять текст запиту.
Діє принцип найменшого подиву, користувач зазвичай очікує побачити шукані слова в текстах отриманих сторінок. Крім того, що використання кешованих сторінок прискорює пошук, сторінки в кеші можуть містити таку інформацію, яка вже ніде більше не буде доступною.
Пошуковик працює з вихідними файлами, отриманими від індексатора. Пошуковик приймає запити користувачів, обробляє їх за допомогою індексу і повертає результати пошуку.
Корисність пошукової системи залежить від релевантності знайдених нею сторінок. Релевантність в пошуку-відповідність пошукового запиту і пошукового образу документа. У більш загальному сенсі одне з найбільш близьких поняттю «релевантності» - «адекватність», тобто не тільки оцінка ступеня відповідності, але і ступеня практичної застосовності результату.
Хоч мільйони веб-сторінок і можуть включати якесь слово або фразу, але одні з них можуть бути більш релевантні, популярні або авторитетні, ніж інші. Більшість пошукових систем використовує методи ранжирування, щоб вивести в початок списку «кращі» результати. Пошукові системи вирішують, які сторінки більш релевантні, і в якому порядку повинні бути показані результати, по-різному.
З тим, як працює гугловський алгоритм PageRank, вам допоможе інфографіка (на жаль, англійською, можна збільшити):
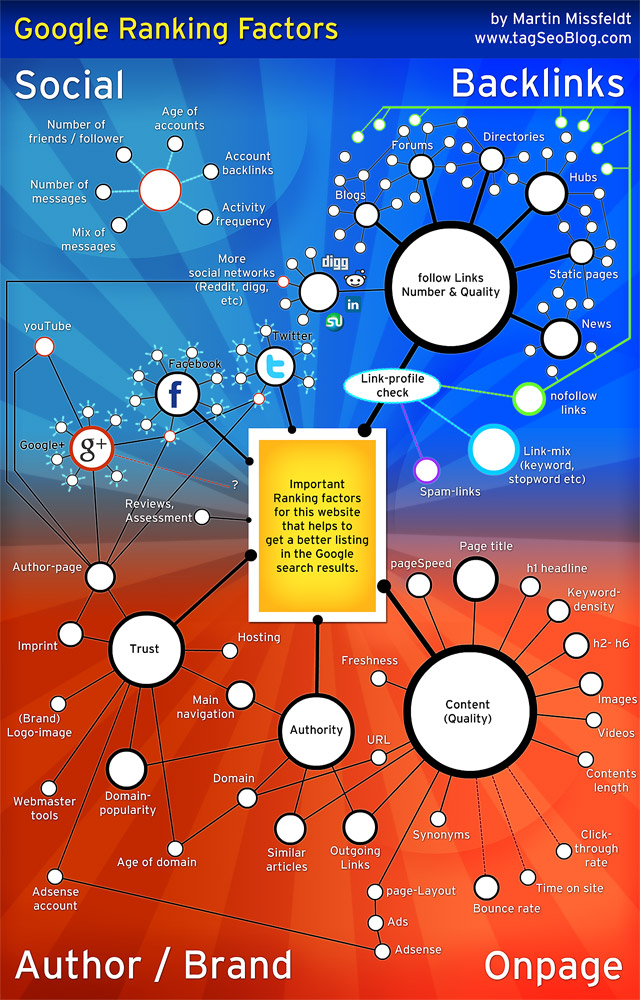
Ще одна інфографіка пояснює, які чинники впливають на релевантність сторінок в Google:
З історією Google ви можете познайомитися в фільмі "Погляд зсередини: Google":
Також рекомендую вашій увазі лекцію Сергія Бріна і Ларрі Пейджа на конференції TED:
Служба World Wide Web (WWW) - найпопулярніша служба сучасного Інтернету. Саме її нерідко ототожнюють з Інтернетом в цілому, хоча насправді це лише одна з його численних служб.
Засновник мережі Тім Бернес-Лі дав таке визначення:
WWW - це мережа серверів, розподілена гетерогенна (тобто неоднорідна) інформаційна мультимедіа-система колективного користування.
З визначення зрозуміло, яку величезну роль в сучасному суспільстві має комп'ютерне інформаційне середовище. Середа WWW не має централізованої структури. Всі, хто бажає розмістити в Інтернеті свої матеріали, що не суперечать законодавству, можуть це зробити.
Окремий документ World Wide Web називають Web-сторінкою. Зазвичай це комбінований документ, який може містити текст, графічні ілюстрації, мультимедійні та інші об'єкти. Відмінною особливістю середовища WWW є наявність засобів переходу від одного документа до іншого, тематично з ним пов'язаного, без явної вказівки адреси. Зв'язок між документами здійснюється за допомогою гіпертекстових посилань. Величезне число гіпертекстових електронних документів, що зберігаються на серверах WWW, утворює своєрідне гіперпростір документів, між якими можливе переміщення.
Термін "гіпертекст" вперше був введений Тедом Нельсоном в 1960-х роках. Поняття "гіпертекст" позначає електронний документ, який містить в собі посилання на інші документи.
HTML (HyperText Narkup Language) - це тегів мову розмітки документів. Команди мови HTML називаються тегами (англ. Tag - відмітка, «пташка»).
Розробка HTML призвела в підсумку до нової технології поширення гіпертекстових документів в Internet. Однак для широкого поширення WWW, крім мови HTML, потрібна була розробка протоколу передачі гіпертексту HTTP (HyperText Transfer Protocol - протокол передачі гіпертексту), який дозволив здійснювати обмін документами HTML. Саме цей протокол дав можливість додатку-клієнта знаходити і використовувати ресурси, що зберігаються на іншому комп'ютері. Протокол HTTP займається пошуком і завантаженням потрібного документа.
Перші HTML-документи, що зверталися в Internet на початку 90-х років, були виключно текстовими. Так було до тих пір, поки в NCSA (Національний центр дослідження надпровідників) Іллінойського університету ні розроблений перший графічний інтерфейс (Mosaic) для HTML-документів. Згодом з появою безлічі простих і доступних браузерів для Web і для інших служб Internet почалася нова ера для HTML. Мова HTML став основним інструментом для поширення інформації в Internet, хоча спочатку він призначався для організації інформації в межах одного наукового центру.
Зв'язок між сотнями мільйонів документів, що зберігаються на фізичних серверах Інтернету, не могла б існувати, якби кожен документ в цьому гіперпросторі не володів своїм унікальним адресою. Файл одного локального комп'ютера володіє унікальним повним ім'ям, до якого входить власне ім'я файлу з розширенням і шлях доступу до файлу, починаючи від імені пристрою, на якому він зберігається. Визначаючи місце розташування файлу в Глобальній мережі, треба розширити уявлення про унікальний імені файлу.
Адресний рядок браузера
Адреса будь-якого файлу у всесвітньому масштабі визначається уніфікованим покажчиком ресурсу - URL. URL-адреса являє собою стандартизовану рядок символів, що вказує місцезнаходження ресурсу, документа або його частини в Інтернеті, і складається з трьох частин:
ім'я протоколу для доступу до послуги Інтернет;
ім'я сервера, на якому зберігається ресурс і працює сервер-програма служби Інтернет;
повне ім'я файлу, який зберігається на сервері.
Формат URL-адресу
Для функціонування служби Інтернет необхідно серверне та клієнтське програмне забезпечення. Роботу служби World Wide Web забезпечують серверні програмні засоби - Web-сервери, і клієнтські програми - Web-браузери.
Документальний фільм "Завантаження: справжня історія інтернету. Битва браузерів":